Scraping Entourage
Early last year myself and my flatmate got into Entourage, which is incredible. We devoured all eight seasons in a few weeks. One thing that I love about it is the soundtrack. It’s a mix of older and newer stuff and, frankly, I have no idea about music so it’s nice to have a pool of well-picked tracks to dip in to.
In December, when my flatmate rewatched the series, I decided to do something with the soundtrack. Getting the music (for 96 episodes) wasn’t as easy as downloading an album — it took some programming, a few headaches, and a bit of tedium. What follows was ultimately successful, but I’d hesitate to call it a success story.
Sourcing the music
HBO’s website does list the tracks used in each episode, but you can’t get at them as it’s all Flash. However, Tunefind has good data, which I imagine some industrious person has transcribed from the official list. In some cases it’s more complete.
But the advantages of having users assemble such data are weighed against the mistakes they may make and inconsistencies that creep in. I’ll address the practical implications later. First we need to extract the track details from the website.
The programs in this post are incredibly rough. I share them in the hope they’ll help others and spark ideas, not as good examples.
All of the code is collected in a multi-file Gist.
1#!/usr/local/bin/python3
2
3import re
4import json
5from bs4 import BeautifulSoup
6from urllib.request import urlopen
7
8base_url = 'http://www.tunefind.com'
9seasons_index = '/show/entourage'
10response = urlopen(base_url + seasons_index)
11response_text = response.read().decode()
12soup = BeautifulSoup(response_text)
13
14seasons_div = soup.find('div', class_='lefttext sidebarIndent')
15seasons_urls = [(base_url + a_tag['href'])
16 for a_tag in seasons_div.find_all('a')]
17
18tracks_list = []
19
20for s in seasons_urls:
21 season = BeautifulSoup(urlopen(s).read().decode())
22 episode_urls = [(base_url + a_tag['href']) for a_tag
23 in season.find_all('a',
24 {'name': re.compile(r'episode\d+')})]
25
26 for e in episode_urls:
27 episode = BeautifulSoup(urlopen(e).read().decode())
28
29 for raw in episode.find_all(class_='tf-songevent-text'):
30 match = re.search(r'(.+)\n\s+by (.+)', raw.text.strip())
31 if match:
32 tracks_list.append(match.groups())
33
34for track in tracks_list:
35 # filter list for duplicates
36 if tracks_list.count(track) > 1:
37 tracks_list.remove(track)
38
39with open('/Users/robjwells/Desktop/tracks.json', 'w') as tracks_json:
40 json.dump(tracks_list, tracks_json)
Tunefind’s website has index pages for each series with links to each of their seasons, which link to pages for each episode that contain track details. The scraping code iterates over the seasons (lines 14–24), then the episodes (lines 26–32).
The loop starting on line 20 appends a tuple of the track title and artist name, found in line 30, to tracks_list. This is bluntly weeded for exact duplicates in lines 34–37. (Subtly different entries for the same track aren’t affected, so they have to be picked out when adding the tracks to Spotify, detailed below.)
Lastly the list is written to a file; I chose JSON because I wasn’t sure what I was going to do next. The tuples are converted to lists, which is fine for our purposes.
Doing something with it
We’ve now got a nice file of titles and artists — 789 tracks in total. The next question is how to use it. My goal was to construct a Spotify playlist, as the service has a large catalogue of tracks available for free and it would take no effort to use once set up.
Initially I considered using the Spotify API, but it appeared too daunting and the quality of the data would derail attempts to add tracks programmatically. Instead I settled on scripting the desktop client. That’s easier said than done, as its AppleScript support is poor.
When I publish I always check the post’s links. Thank god I did, because Spotify has recently overhauled its developer site. The metadata API looks far more approachable.
However, discrepancies between the Tunefind data and Spotify’s catalogue would still likely cause headaches. Also, adding tracks to a playlist is still reserved for its C API.
After mulling over how much manual work I was willing to do, I came up with the idea for an AppleScript scaffold that, since I couldn’t script Spotify directly, would script around Spotify: using its URL scheme to search for tracks and a dialog box with controls to move through the list.
Underneath that would be Python that managed the track list, assembled the URL and handled the controls:
1#!/usr/local/bin/python3
2
3import json
4import subprocess
5
6position = open('/Users/robjwells/Desktop/position', 'r+')
7reported = open('/Users/robjwells/Desktop/reported', 'a')
8
9
10def asrun(script):
11 "Run the given AppleScript and return the standard output and error."
12
13 osa = subprocess.Popen(['osascript', '-'],
14 stdin=subprocess.PIPE,
15 stdout=subprocess.PIPE)
16 return osa.communicate(script.encode())[0]
17
18
19with open('/Users/robjwells/Desktop/tracks.json') as tracks_json:
20 tracks_list = json.load(tracks_json)
21
22ascript = '''
23tell application "LaunchBar"
24 perform action "Open Location" with string "spotify:search:{0}"
25end tell
26
27tell application "Finder"
28 set dialog_result to display dialog "Ready for next track?" ¬
29 buttons {{"Report", "Stop", "Next"}} default button "Next"
30 return button returned of dialog_result
31end tell
32'''
33
34
35def prep_track(t):
36 joint = ' '.join(t)
37 return joint.replace(' ', '+')
38
39
40def prompt(t):
41 script = ascript.format(prep_track(t))
42 result = asrun(script).decode().strip()
43 if result == 'Stop':
44 return False
45 elif result == 'Report':
46 reported.write(json.dumps(t))
47 reported.write('\n')
48 position.seek(0)
49 position.write(str(tracks_list.index(t) + 1))
50 return True
51
52
53raw_pos = position.read()
54if raw_pos:
55 pos = int(raw_pos)
56else:
57 pos = 0
58
59for track in tracks_list[pos:]:
60 if not prompt(track):
61 break
62
63position.close()
64reported.close()
According to the file metadata, I created this script at 12.50am. Some of it is hilariously bad. I haven’t tidied up these scripts but I had to change a bit where I trampled all over my own global names. It’s in desperate need of re-ordering so I’m going to work through the script in the order parts are used, not in which they’re written.
At its core, it’s a little Python engine that uses Dr Drang’s asrun function to run an AppleScript via osascript.
We start by opening a position file to store our place in the track list and a reported file to store any tracks which aren’t in the Spotify catalogue (lines 6 & 7). Next we open and parse the JSON track list (lines 19 & 20).
Lines 53–57 determine from the position file where to begin in the track list, with pos used to slice it in line 59. The selected part of the list is iterated over and each track tuple fed to the prompt function (lines 40–50).
This formats the track (using prep_track to join the artist and title, and replace spaces with plus signs) and inserts it into the AppleScript (line 41), which is then run.
The AppleScript opens the Spotify search URL and displays a dialog box:
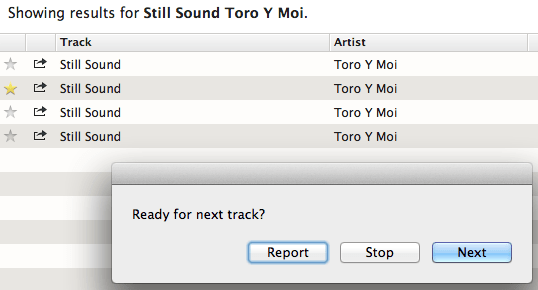
The chosen button is returned and assigned to result. If the searched-for track couldn’t be found, the “Report” button adds it to the reported file (lines 46 & 47) and proceeds as if “Next” had also been clicked: writing the index of the next track to the position file and returning True to cause the loop in lines 59–61 to continue. “Stop” returns false and ends the loop — and so the script.
Within the AppleScript itself (lines 22–32), LaunchBar is used to open the Spotify. This is holdover from when I was trying to use LaunchBar’s “Browse in Spotify” action (select Spotify and press space) instead of the search URL. It didn’t work. There’s no reason to use LaunchBar anymore, this would work fine:
open location "search:spotify:{0}"
Where {0} is a replacement field.
Once the sliced list has been iterated over, we clean up by closing the position and reported files (lines 63 & 64).
The script does a decent job of working around the inability to directly control Spotify. It leaves me to pick an appropriate track from the search results shown, drag it to a playlist and chose the appropriate next action from the dialog. It turned a mountain of tedious work into a reasonably-sized hill.
Being human, though, I occasionally picked the wrong button in the dialog, meaning some tracks weren’t reported or were reported in error. Ah well. I was still left with a playlist of about 570 tracks.
A musical interlude
Since creating it in mid-December, I’ve been listening to the playlist and marking my favourite tracks so I could buy them on iTunes. There’s too many to do by hand, so a bit of automation is called for.
Dragging a track from the Spotify client gives you an http://open.spotify.com/track/… URL. Opening it in a browser will likely get you the newfangled web player, which isn’t much use, but tools such as curl still return the source to the detail view you used to get. We’ll use this to turn the URLs back into track titles and artist names, and from there into iTunes links.
1#!/usr/local/bin/python3
2
3import os
4import sys
5import requests
6from bs4 import BeautifulSoup as bs
7
8spot_path = os.path.join(os.getcwd(), sys.argv[1])
9itunes_search = 'https://itunes.apple.com/search?term={}&country=gb'
10
11with open(spot_path) as spot_file:
12 spot_links = spot_file.read().splitlines()
13
14
15def spotify_to_itunes(link):
16 spot_soup = bs((requests.get(link)).text)
17 title = spot_soup.h1.text
18 artist = spot_soup.h2.a.text
19 plussed = '+'.join([title, artist]).replace(' ', '+')
20 itunes_response = requests.get(itunes_search.format(plussed))
21 if itunes_response.json()['resultCount']:
22 return itunes_response.json()['results'][0]['trackViewUrl']
23 else:
24 return ' '.join([artist, title])
25
26for line in spot_links:
27 print(spotify_to_itunes(line))
Dragging several tracks from Spotify gives you URLs separated by newlines, which I saved to a file that is read and split in lines 11 & 12. We iterate over each URL at the end of the script, printing the result of passing the URL to spotify_to_itunes, which does the hard work.
We get the source for the track’s detail view in line 16 and pull out the title and artist, which are joined and the spaces replaced with plus signs in line 19 to make the string URL safe — like in the previous script.
This combined string is used to search the iTunes catalogue (line 20, with the URL in line 9). If there are any results we return the URL for the top hit, otherwise we return the artist name and track title so it can be looked up manually.
Taking the URL for the top iTunes result is potentially hazardous, but here I’m happy enough to put my faith in its search. Also the script takes two requests to process each track (lines 16 & 20) so it is slow, but as it only needs to be run once so I don’t think it really matters.
I decided not to rig up the AppleScript side here, because in my mind it doesn’t require the same kind of industrial processing. At this point it’s a matter of taking time to listen to the track previews and decide which to buy.
Also in contrast to the previous scripts, I print to stdout here instead of writing directly to a file. I don’t have reason for this but I guess partly it’s because there’s no data structure to preserve, just a set of lines to transform.
At this point I’ve run the script and redirected the output to a file. My plan is open it in BBEdit and use ⌘L to select each, send it to LaunchBar (using the Instant Send feature) and open the URLs in Safari and the leftover tracks in iTunes’s search. Thankfully the iTunes links just load a web preview and don’t activate iTunes itself.
I’ve done this already with the tracks in the reported file, run through a modified version of the above script. It works reasonably well.
Wrapping up
While writing (and re-writing) this post I began to doubt its value. These aren’t polished scripts and this shouldn’t be taken as a guide, but at the same time it is how I solved the problem. Examining the choices made — however little thought went into them — has been instructive for me and hopefully will give people facing similar problems something to think about.
{kind=link}
And while I’d hesitate to call this a real problem, the cobbled-together solution has at least produced something I’m still listening to after two months.